Part 2.
As a reminder, these design details are provided exclusively for the members of this forum and cannot be found anywhere else. © 2020 Scott A. Wilber.
The probability of a tie occurring between two or more of the top-rated bins decreases as the number of bits used in a trial increases. However, from a practical perspective one must assume a tie will occur because it can. One way to break a tie is to add more data until there is a clear winner, that is, a single top-rated bin. This is the approach that will be described in the following, but always consider there are many ways of processing MMI data to achieve the desired result.
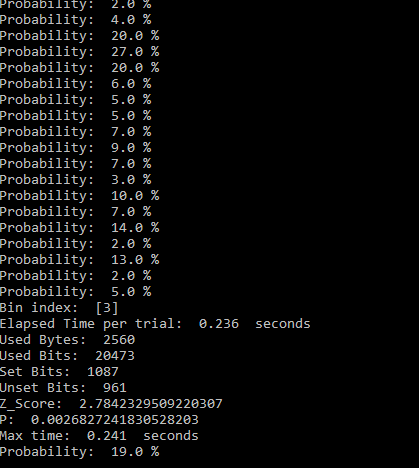
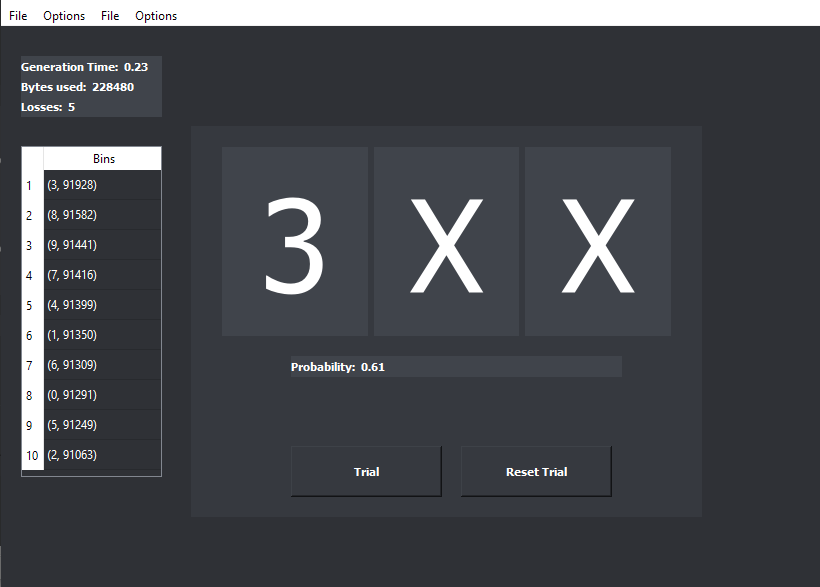
When a trial is initiated by keypress or other method, accumulate the number of 1s in a preselected number of words from the MMI generator and place that number in the bin labeled “0.” Then proceed the same way with the second bin, and so on until all the bins have counts from an equal number of words. It’s not possible to prevent ties by using an odd number of bits as with a two-bin (binary) selection process. Therefore, use all the bits from the selected number of words for each bin.
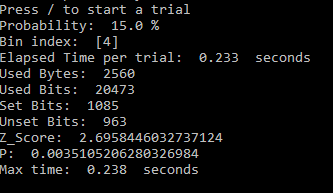
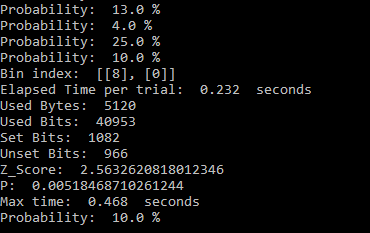
The simplest way to proceed would be to take 256 bytes for each bin, requiring a total of 2560 bytes (20480 bits). This is the output of a MED100Kxx generator in about 0.2 seconds. For a number of reasons, the simplest way is not the best, or at least the better way. Instead, take 64 bytes for each of the bins and repeat that 4 times, increasing the total count in the bins each time. The first reason for accumulating the counts in this way is to avoid as much as possible any conscious or unconscious bias toward any one of the bins/target numbers. After the trial – which I will call provisional because it may not be completed yet – sort the bins from highest to lowest by number of counts of 1s in each. If there is a unique highest count (no ties), the trial is completed. Output the label of the highest bin count as the selected number. If one or more counts are tied for the top position, take another 64 bytes of data for each bin, increasing the provisional counts. Check again to see if there is a clear winner. If there is, the trial is completed and output the label of the bin with the highest count of 1s. Again, if a tie still persists for the top bin(s), continue adding data in blocks of 64 bytes per bin for every bin until there is no tie. This is the second reason for adding data in smaller blocks – tie breakers will take less data versus adding the full amount of data (another 0.2 seconds).
Avoiding mental bias is always an issue in MMI systems, and it’s harder than it sounds. Do not display specific results until a trial or final outcome is produced. When future information or a prediction is being made, specific counts of 1s are inverted using a single random bit produced by a true random generator after the MMI data is produced. Inversion means replacing the counts of 1s by the counts of 0s for the same data block or sub-trial. That prevents the user from intending any of the numbers in a specific bin from being increased. This user bias can occur consciously or unconsciously. Note, the data is not all inverted, only, for example the data for a single bin at a single update (64 bytes in this example). A new random bit is used for deciding whether to invert any block of data in any bin – if the random bit is a 1, invert the count, else do not invert. As an example: if the count of 1s from a 64-bit block is 250 and the invert/non-invert random bit is 1, the resulting count to be added to the bin would be, inverted counts = 512 – 250 = 262. If the random bit is a 0, the count to be added would be unchanged, 250. This is a somewhat complicated processing, and at the developmental first pass can be omitted. It’s also not certain this is the best way to avoid an obvious source of user mental bias.
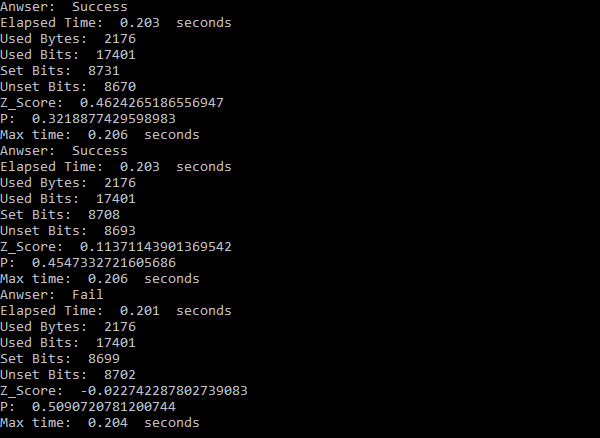
When following the process outlined above, it’s not necessarily enough to get a unique high bin count. One may also require the high count to represent a statistically significant outcome. Statistical significance generally means the probability of the null hypothesis test is 5% or less, though one may desire a more stringent 1% or less. The null hypothesis test is: what is the probability a greater than or equal count of 1s than what actually occurred could have happened by chance, that is, without mental influence. Though it sounds complicated, it’s straight forward test. The bit count data is from the Binomial distribution, but when the number of bits counted is greater than a few hundred, which it is, the Normal distribution approximation can be used with very little error. That means a z-score can be calculated and a simple threshold can be used to determine significance, or preferably, the actual probability can be calculated. The approximate z-score is, z = (2 x 1s – N )/square root N . That is, 2 times the count of 1s minus N , divided by the square root of N . N is the total number of bits in the words used to accumulate the counts of 1s in that bin, or 2048 for this example. If there are ties, N would increase accordingly. The probability of the null hypothesis test is, p = 1 – (cumulative normal distribution function at z ). Numerical Recipes in C , or other online sources can provide the code for the cumulative distribution function. I believe I already provided code for an approximation to that function. If only a threshold is desired, z ≥ 1.6448536 is the 5% significance level, and z ≥ 2.3263478 is 1%. Note, for the statisticians in the group, these tests are one-tailed because I don’t consider so-called Psi-missing, or getting a significant score in the wrong direction, to be in any way useful.
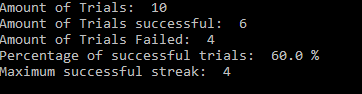
To achieve a particular level of significance will usually require a multi-trial system. That means the user must focus and perform repeated trials until the desired level of significance is reached. When trials are repeated, the counts in the bins are accumulated from trial to trial. In spite of not giving specific feedback during a trial, or a series of trials, some sort of real time feedback is always desirable. In the example, a minimum feedback is the probability or some representation of the probability and whether the desired level of significance has been reached. The bin or number related to the probability should never be displayed until the outcome is reached. There are many possibilities of feedback, and I won’t try to go into them in this message.
I tried to keep this as simple as possible, but the process is not trivial. If anyone is trying to implement this or other similar algorithms, please ask very specific questions.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}